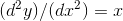El método de bisección en métodos numéricos es utilizado para obtener la raíz de una ecuación. El termino "raíz" se refiere al valor de x que tiene la capacidad de hacer que la ecuación planteada tenga un valor igual, o muy cercano, a cero.
Para implementar el método de bisección en lápiz y papel primero debemos plantear una ecuación problema, nuestra ecuación problema será la siguiente.
f(x)=( x^3)+(4*x^2)-10
El siguiente paso para implementar el método es proponer un intervalo entre el cual creemos que se encuentra la raíz de la ecuación, al valor más pequeño del intervalo le llamaremos "a" y al mayor le llamaremos "b".
La única condición que debe cumplir el intervalo propuesto es que el producto de f(a) y f(b) sea menor a cero.
f(a) * f(b) < 0
The product of f(a) and f(b) must be minor to cero for the ethod to work.
Para nuestra ecuación problema propondremos el intervalo abierto de 1 a 2.
f(a)= 1+4-10 = -5
f(b)= 8+16-10 = 14
Por lo anterior comprobamos que nuestro intervalo cumple con la condición mencionada en el punto anterior.
El siguiente paso será definir el valor de P.
P= a + (b-a)/2
Por lo tanto, para nuestro problema, P tendrá el siguiente valor.
P=1+ (2-1)/2 = 1+ (1/2)= 3/2
El siguiente paso consiste en sustituir el valor de P en nuestra ecuación.
f(P)= (3.375)+9-10= 2.375
El siguiente paso del método será decisivo, requiere de la implementación de las siguientes 3 reglas.
- Si f (P)= 0 entonces P es la raíz de nuestra ecuación.
If f(P) = 0 then P is the root of the equation
- Si f (P) y f(a) tiene el mismo signo, entonces la raíz de la ecuación se encontrará en el intervalo de [P , b]
If f(P) and f(a) have the same sign, then the root will be between the interval [P , b]
- Si f(P) y f(a) tienen signo distinto, entonces la raíz de nuestra ecuación se encuentra en el intervalo de [a , P].
If f(P) and f(a) have different sign, then the root will be between the interval [a , P]
Los anterior significa que , para nuestra ecuación problema el nuevo intervalo se encontrará en
[1 , 2.375]
f(a)= 1+4-10 = -5
f(b)= 8+16-10 = 14
f(P)= (3.375)+9-10= 2.375
El procedimiento anteriormente señalado debe repetirse hasta que se cumpla la primera de las 3 reglas antes mencionadas, o bien, el resultado sea tan pequeño que pueda volverse cero. Por lo tanto, continuaremos con el procedimiento hasta encontrar la raíz de nuestra ecuación problema.
* Segunda iteración.
[1 , 2.375]
f(a)= 1+4-10 = -5
f(b)= (13.39) + 22.56 - 10 = 25.95
P= 1+ (2.375-1)/2 = 1+ 0.6875 = 1.6875
f(P)= 4.805 + 11.39 - 10 = 6.1956
*Tercera iteración [1 , 1.6875]
f(a)= 1+4-10 = -5
f(b)= 4.805 + 11.39 - 10 = 6.1956
P=1+(1.6875-1)/2 = 1+0.3437 = 1.3437
f(P) = 2.4260 + 7.222 -10 = -0.3518
*Tercera iteración [ 1.3437 , 1.6875]
f(a)= 2.4260 + 7.222 -10 = -0.3518
f(b)= 4.805 + 11.39 - 10 = 6.1956
P= 1.3437 +(1.6875-1.3437)/2= 1.5156
f(P)= 3.4813+ 9.1881 - 10 = 2.6694
*Cuarta iteración [1.3437 , 1.5156]
f(a)= 2.4260 + 7.222 -10 = -0.3518
f(b)= 3.4813+ 9.1881 - 10 = 2.6694
P= 1.3436+(1.5156 - 1.3437)/2 = 1.4296
f(P) = 2.8220 + 8.1750 - 10 = 0.9970
*Quinta iteración. [1.3437 , 1.4296]
f(a)= 2.4260 + 7.222 -10 = -0.3518
f(b) = 2.8220 + 8.1750 - 10 = 0.9970
P= 1.3437 + ( 1.4296-1.3437)/2 = 1.3866
f (P) = 2.666 + 7.69 - 10 = 0.35063
*Sexta iteración [1.3437 , 1.3866]
f(a)= 2.4260 + 7.222 -10 = -0.3518
f(b) = 2.666 + 7.69 - 10 = 0.35063
P= 1.3437+ (1.3866-1.3437)/2 = 1.36515
f(P)= 2.5441 + 7.4539 - 10 = - 0.00190
Se puede observar que en la sexta iteracion f (P) es aproximadamente cero, por lo tanto, la raíz de la ecuación es aproximadamente 1.3651.
Como se puede ver, el procedimiento es largo y tedioso, y, si te estabas preguntando para que sirve la tan mencionada raíz, pues resulta que la raíz representa un valor de x que satisface la ecuación, por lo tanto, si aplicamos este método a una ecuación cuadrática sería posible obtener el valor de x. A través del uso de este método es posible encontrar solución a ecuaciones cuadráticas o, incluso, de niveles más altos siempre y cuando se cumplan todas las reglas antes mencionadas. Por supuesto no tendría sentido aplicar el método a mano debido a la cantidad de esfuerzo que ello representa y al desconocimiento de la cantidad de iteraciones necesarias para llegar a una solución precisa, por fortuna el uso de los lenguajes de programación hace mucho mas fácil está tarea. Si quieres saber más sobre el código en MATLAB para este procedimiento, revisa nuestra sección de Métodos numéricos en MATLAB